Debug long running Spark job

You Spark job is running for a long time, what to do?
Generally, long-running Spark jobs can be due to various factors. We like to call them the 5S - Spill, Skew, Shuffle, Storage, and Serialization. So, how do we identify the main culprit?
🔎 Look for Skew: Are some of the tasks taking longer than others? Do you have a join operation?
🔎 Look for Spill: Any out-of-memory errors? Do the executors have enough memory to finish their tasks? Got any disk spills?
🔎 Look for Shuffle: Large amounts of data being shuffled across executors? Do you have a join operation?
🔎 Look for Storage Issues: Do you have small files or highly nested directory structure?
🔎 Look for inefficient Spark code, or serialization issues.
Now, the solution may vary depending on the root cause. Most of the times, the root cause indicators will show up in the SparkUI and it’s important that you understand how to read it.
In general, always try to cut down the time Spark takes to load data into memory, parallelize tasks across executors, and scale the memory according to data size.
Skew [imbalance partitions]
TL,DR - Skew is caused by imbalance partitions. To fix Skew, try to repartition data, or set SkewHint when reading in data from disk to memory. If Skew is caused by partition imbalance after shuffling stage, enable SkewJoin option with Adaptive Query Execution, and set the correct shuffle partitions size. In most cases, turning on Adaptive Query Execution can help mitigate Skew issue.
Let's talk about one of the most common issues you might encounter in Spark - "skew". Skew refers to an imbalance in partition sizes, which can also lead to a spill. When you read in data in Spark, it's typically divided into partitions of 128 MB, distributed evenly according to the maxPartitionBytes setting. However, during transformations, Spark will need to shuffle your data, and some partitions may end up having significantly more data than others, creating skew in your data.
When a partition is bigger than the others, the executor will take longer to process that partition and need more memory, which might eventually result in a spill to disk or Out Of Memory (OOM) errors.
How do you identify Skew in your SparkUI?
- If you see long running tasks and/or uneven distribution of tasks in the Event Timeline of a long-running stage
- If you see uneven Shuffle Read/Write Size in a stage’s Summary Metrics
- Skew can cause Spill, so sometimes you will see Disk or Memory Spill as well. If Spill is caused by Skew, you have to fix Skew as the Root cause.
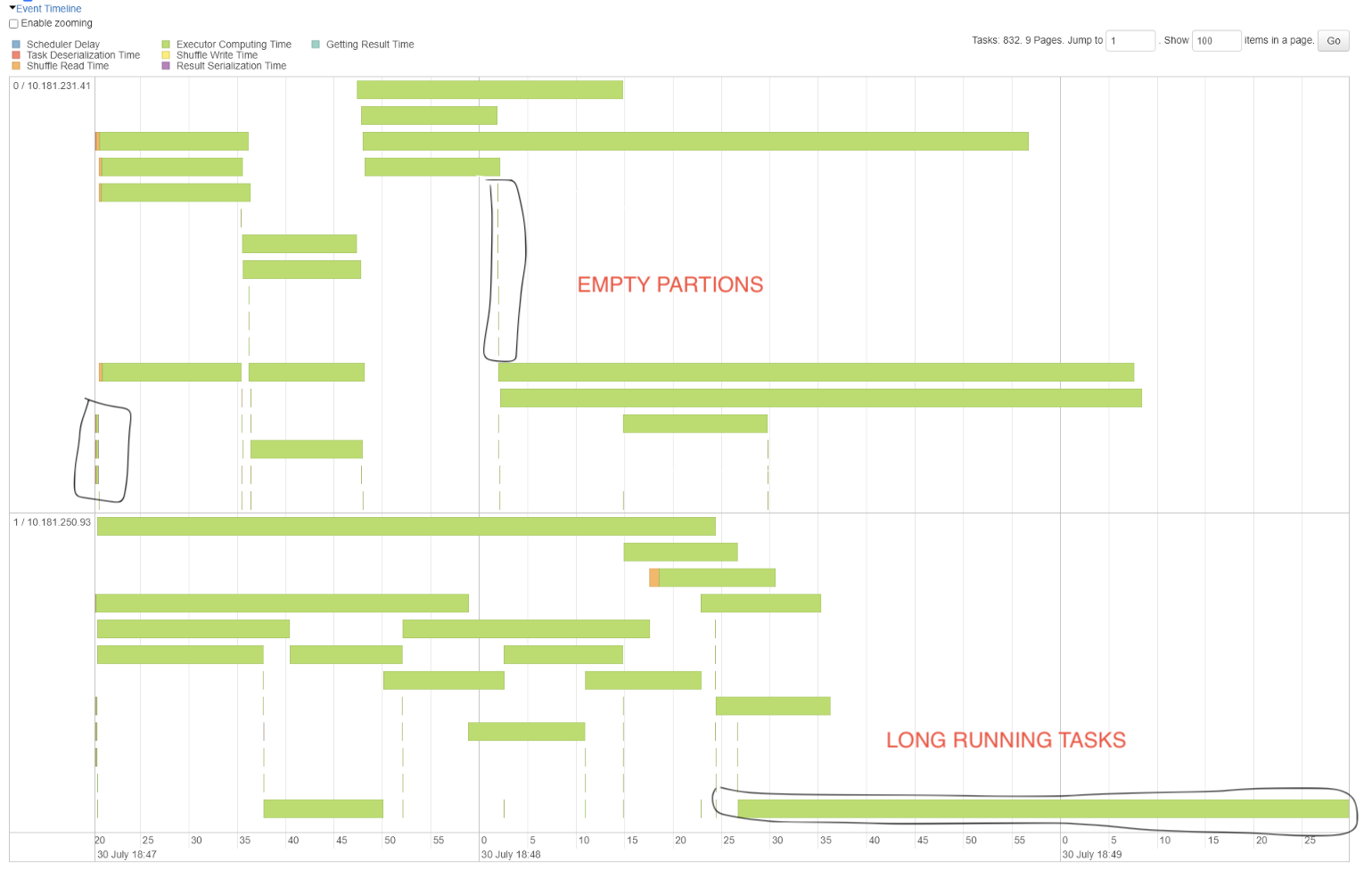
How do you fix Skew?
If you disk spill or OOM errors are caused by skew, instead of solving for RAM problem, solve for uneven distribution of records across all partitions
Option 1: If you run Spark on Databricks, use skew hint (refer Skew Join optimization). For example, assuming that you know the column used in the join is skewed, set the skew hint for that column. With this skew hint information, Spark can hopefully construct a better query plan for the join
## Set skew hint when loading the table
df = spark.read.format("delta").load(trxPath)
.hint("skew","<join_column>") Option 2: If you use Spark 3.x, utilize Adaptive Query Execution (AQE). AQE can automatically adapt query plans at runtime based on more accurate metrics, leading to more optimized execution. After a shuffle, AQE can automatically use split shuffle read to split skewed partitions into smaller partitions, ensuring that the executors are not burdened by larger skews. This can lead to faster query execution and a more efficient use of cluster resources. Using AQE is highly recommended, and generally more effective than other options
## Turn AQE on
spark.conf.set('spark.sql.adaptive.enabled', True)
spark.conf.set('spark.sql.adaptive.skewedJoin.enabled', True)Option3 : Another option is to salt the skewed column with a random number to create more evenly partitions but at the cost of extra processing. This is a more complex operations, which we should discuss in another post.
Spill [lack of memory]
TL,DR - Spill is caused by executors lacking of memory to process partitions. To fix Spill think about how you can add more memory to the executors, or manage the partitions sizes
If your Spark executors don’t have enough local memory to process their allocated partitions, Spark has to spill the data to disk. Spill is a Spark’s measure of moving an RDD from local RAM to disk and then back to executor’s RAM again for further processing with the goal of avoiding an out-of-memory (OOM) error. However, this can lead to expensive disk reads and writes, and significantly slow down the entire job.
This process occurs when a partition becomes too large to fit into RAM, and it may be a result of skew in the data. Some potential causes of spill include setting spark.sql.files.maxPartitionBytes too high, using explode() on an array, performing a join or crossJoin of two tables, or aggregating results by a skewed column.
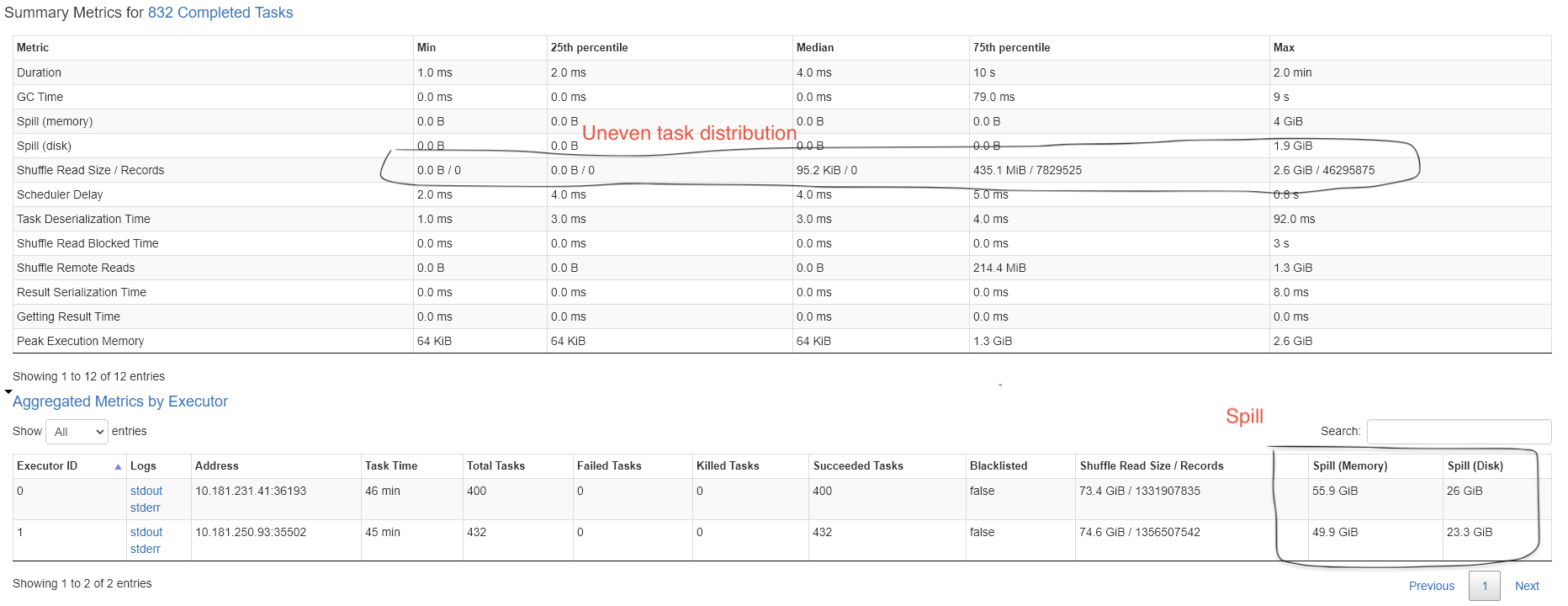
How do you identify Spill in your SparkUI?
You can find Spill indicators on SparkUI under each stage’s detail tabe or Aggregated Metrics by Executor. When data is spilled, both the size of the data in memory and on disk will be provided. Typically, the size on disk will be smaller due to compression that occurs when serializing data before it is written to disk.
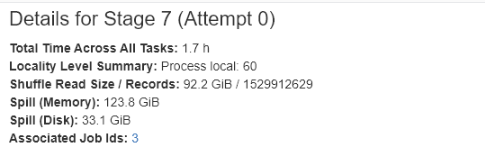

How do you fix Spill?
To mitigate Spill issues, there are several actions you can take.
- First, make sure to fix the root cause of skew if this is the underlying issue behind the spill. To decrease partition sizes, increase the number of partitions or use explicit repartitioning.
- If above doesn’t work, allocate a cluster with more memory per worker if each worker need to process bigger partitions of data.
- Finally, you can adjust specific configuration settings using
spark.conf.set()to manage the size and number of partitions.- manage
spark.conf.set(spark.sql.shuffle.partitions, {num_partitions})to reduce data in each partition shuffled across executors - manage
spark.conf.set(’spark.sql.files.maxPartitionBytes’, {MB}*1024*1024)to reduce size of partition when Spark read from disk to memory
- manage
It's worth noting that ignoring spill may not always be a good idea, as even a small percentage of tasks can delay an entire process. Therefore, it's important to take note of spills and manage them proactively to enhance the performance of your Spark jobs.
Shuffles [data transfer]
TL,DR - Shuffle refers to the movement of data across executors, and it's inevitable with wide transformation jobs. To tune shuffle operations, think about how you can reduce the amount of data that get shuffled across the cluster network
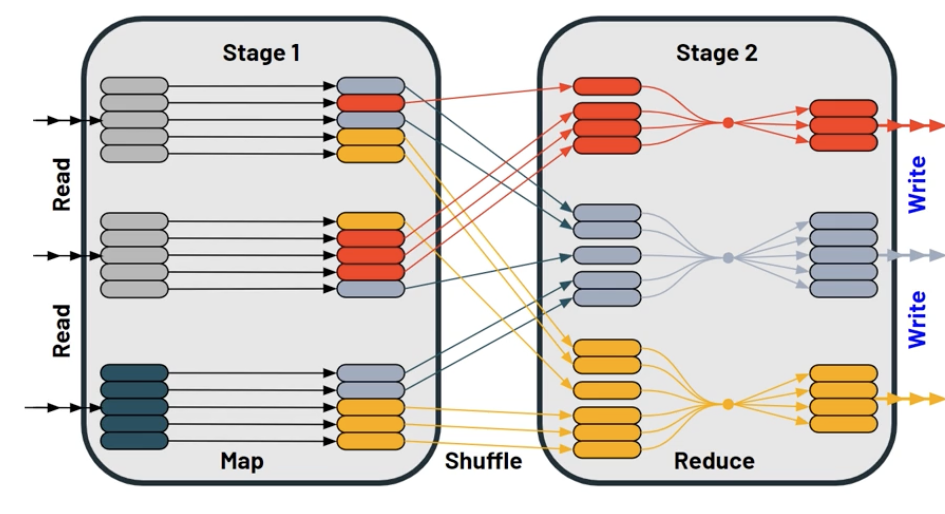
Shuffle is the act of moving data between executors. If you have multiple data partitions in different executors on a Spark cluster, shuffle is necessary and inevitable. Most of the time, shuffle operations are actually quite fast. However, there are situations when shuffle can become the culprit of slowing down your Spark job. For example, moving data across the network is slow, and the more data you have to move, the slower it will get. Moreover, Incorrect shuffles can cause Skew, and potentital Spill
How to identify Shuffle?
If you use wide transformation (distinct, join, groupBy/count, orderBy, crossJoin) in your Spark job and you have multiple executors in the Spark cluster, shuffle will most likely happen.
In the SparkUI, you can find the Shuffle Read Size and Shuffle Write Size numbers in the stages on the SparkUI
How to mitigate Shuffle?
To reduce the impact of shuffle on your Spark job, try to reduce the amount of data you have to shuffle across network
1. Tune the Spark Cluster
- Use fewer and larger workers: You normally pay the same unit price for the same total number of cores and memory in your cluster, no matter the number of executors. So if you have jobs that require a lot of wide transformations, choose the bigger instance and less workers. That way you don't have many executors to exchange data.
2. Limit shuffled data and tune the shuffle partitions
- Use predicate push down and/or narrow the columns to reduce the amount of data being shuffled
- Turn on Adaptive Query Execution (AQE) to dynamically coaslesce shuffle partitions at runtime to avoid empty partitions
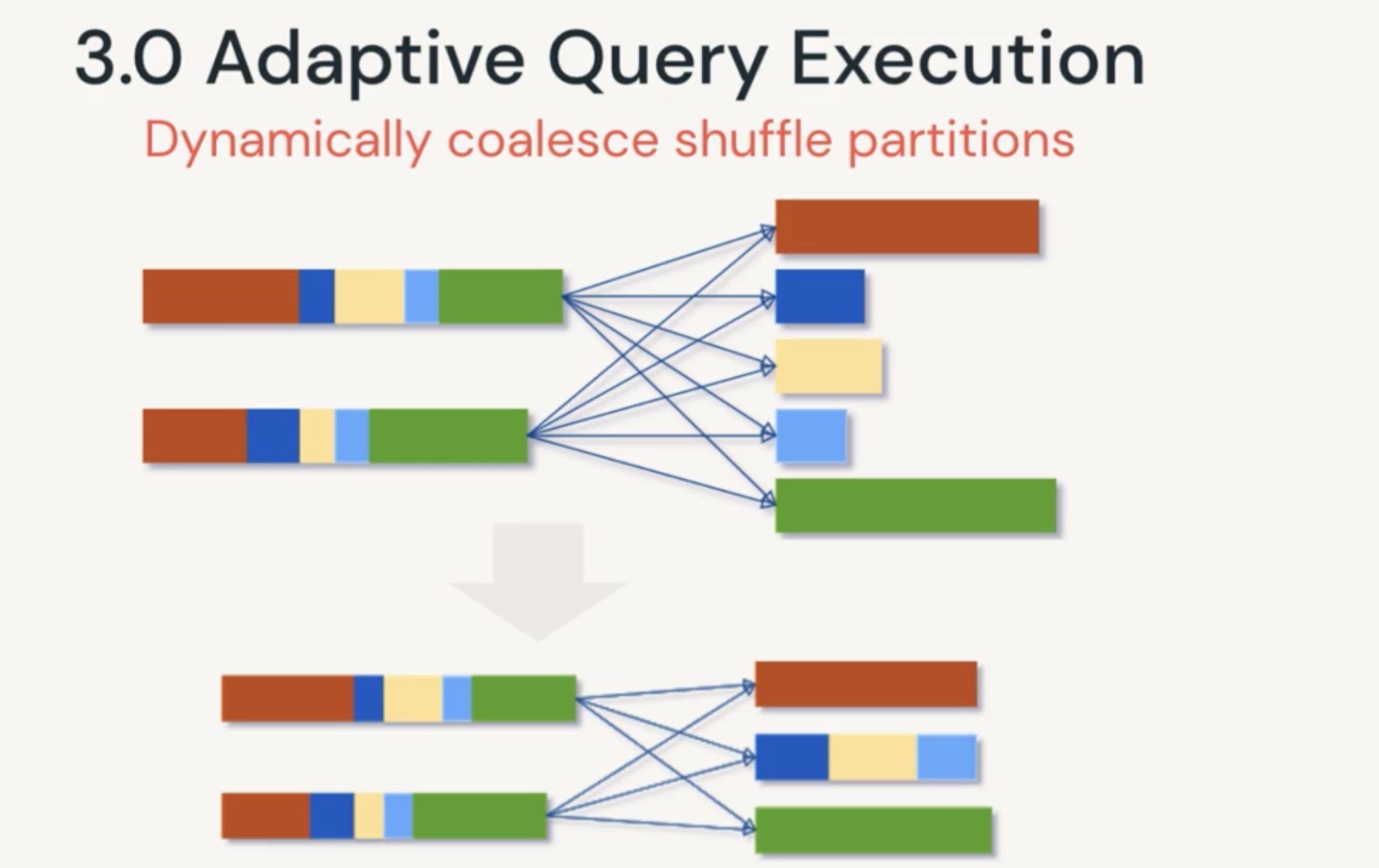
- manage spark.conf.set(spark.sql.shuffle.partitions, {num_partitions}) to set the number of partitions to be shuffled
3. Try BroadcastHashJoin if possible
- Use BroadcastHashJoin if 1 table is less than 10MB. With BHJ, the smaller table will be broadcasted to all executors, which can eliminate the shuffle of data.
- Step 1: each executor will read in their assigned partitions from the bigger table
- Step 2: every partition of the broadcasted table is sent to the driver (therefore you want to make sure the broadcasted table is small enough to fit into the driver mem)
- Step 3: a copy of the entire broadcasted is sent to each executor
- Step 4: each executor can do a standard join between tables because they have the full copy of the broadcasted table, therefore shuffle can be avoided in join
- There are few considerations when it comes to BroadcastHashJoin you should be aware of that we can discuss in another post
- With Adaptive Query Execution in Spark 3.x, Spark will try to do BHJ in runtime if one of the table is small enough
4. Bucketing
Bucketing can be a useful technique to improve the efficiency of data processing by pre-sorting and aggregating data in the Join operation. The process involves dividing the data into N buckets, with both tables requiring the same number of buckets. This technique can be particularly effective for large datasets of several TBs, where data is queried and joined repeatedly.
Bucketing should be performed by a skilled data engineer as part of the data preparation process. It's worth noting that bucketing is only worthwhile if the data is frequently queried and joined, and filtering does not improve the join operation.
By using bucketing in the Join operation, the process of shuffling and exchanging data can be eliminated, resulting in a more efficient join.
Storage [small files, scanning, inferring schema/schema evolution]
TL,DR - Storage issues are problems related to how data is stored on disk, which can lead to high overhead with ingesting data by open, read, close files operation. To fix issues relating to Storage, think about how you can reduce the read, write, ingest files on disk
How to Identify storage issue?
There are a few storage-related potential issues that can slow down operations in Spark data processing. One is the overhead of opening, reading, and closing many small files. To address this, it's recommended to aim for files with a size of 1GB or larger, which can significantly reduce the time spent on these operations.
Another is directory scanning issue which can arise with highly partitioned datasets that have multiple directories for each partition, requiring the driver to scan all of them on disk. For example, files on your storage are fine-grained partitioned to year-month-date-minute.
A third issue involves schema operations, such as inferring the schema for JSON and CSV files. This can be very costly, requiring a full read of the files to determine data types, even if you only need a subset of the data. By contrast, reading Parquet files typically only requires one-time reading of the schema, which is much faster. Therefore, it's recommended to use Parquet as file storage for Spark considering that Parquet stores schema information in the file
However, schema evolution support, even with Parquet files, can also be expensive, as it requires reading all the files and merging the schema collectively. For this reason, starting from Spark 1.5, schema merging is turned off by default and needs to be turned on by setting the spark.sql.parquet.mergeSchema option.
How to fix storage issue?
To address the issue of tiny files in a storage location, if you are using Delta Lake, consider using autoOptimize with optimizeWrite and autoCompact features. These will automatically coalesce small files into larger ones, however they have some subtle differences:
- Auto compaction occurs after a write to a table has succeeded and runs synchronously on the cluster that has performed the write. Auto compaction only compacts files that haven’t been compacted previously.
- Optimized writes improve file size as data is written and benefit subsequent reads on the table. Optimized writes are most effective for partitioned tables, as they reduce the number of small files written to each partition.
To address the issue of slow performance when scanning directories, consider registering your data as tables in order to leverage the metastore to track the files in the storage location. This may have some initial overhead, but will benefit you in the long run by avoiding repeated directory scans.
To address issues with schema operations, one option is to specify the schema when reading in non-Parquet file types, though this can be a time-consuming process. Alternatively, you can register tables so that the metastore can track the table schema. The best option is to use Delta Lake which offer zero reads of schema with a metastore, and at most one reads for schema evolution. Delta Lake also provides other benefits such as ACID transactions, time travel, DML operations, schema evolution, etc.
Serialization [API, programming]
TL,DR - Bad codes can also slow your Spark down, always try to use spark sql built-in functions and avoid UDFs when develop your Spark codes. If UDFs are needed, try vectorized UDFs for Python and Typed Transformations for Scala
Refer to my post about SparkSQL Programming to understand the difference between built-in functions, UDFs and vectorized UDFs
Slower Spark Jobs can sometimes occur as a result of suboptimal code. One example of this would be code segments that have not been reworked to support more efficient Spark operations.
As a rule of thumb, always use spark.sql.functions whenever possible, regardless of which language you're using. You can expect similar performance for both Python or Scala with these functions
In Scala, if you have to use User-defined functions that are not supported by standard spark functions, it's more efficient to use Typed transformations instead of standard Scala UDFs. In general, Scala is more efficient than Python with UDFs and Typed transformation.
If you're working with Python, avoid using Spark UDFs and vectorized UDFs if possible. But if you have to use UDF, always use vectorized UDF