Spark SQL Programming Primer

TL,DR - SparkSQL is a huge component of Spark Programming. This post introduces programming in SparkSQL through Spark DataFrame API. It's important to be aware of Spark SQL built-in functions to be a more efficient Spark programmer
What is SparkSQL
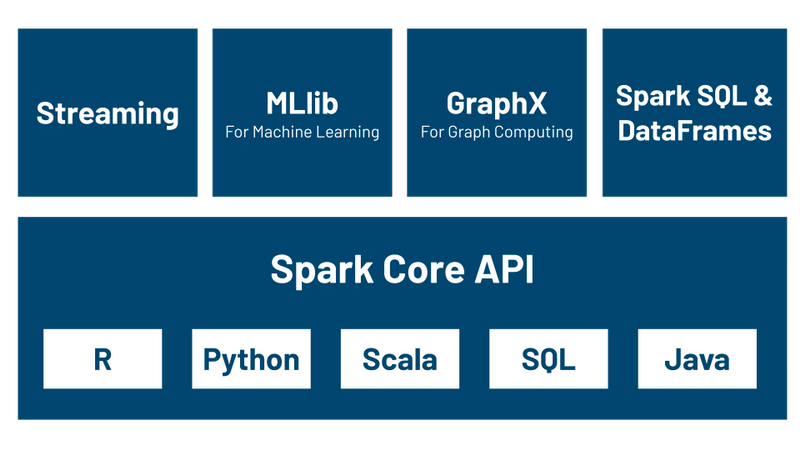
SparkSQL is one of the 4 APIs in Spark ecosystems. SparkSQL provides structured data processing with interfaces such as SQL or Dataframe API using Python, Scala, R, Java programming languages
The same SparkSQL query can be expressed with SQL and DataFrame API. SQL queries, Python DataFrame and Scala DataFrame Queries will then be executed on the same engine. The queries will go through Query Plans, RDDs then Execution. SparkSQL always optimizes the queries before execution using Catalyst Optimizer
-- sql
select a, b from <table> where a > 1 order by b## python
df = spark.table('<table>')
.select('a', 'b')
.where('a>1')
.orderBy('b')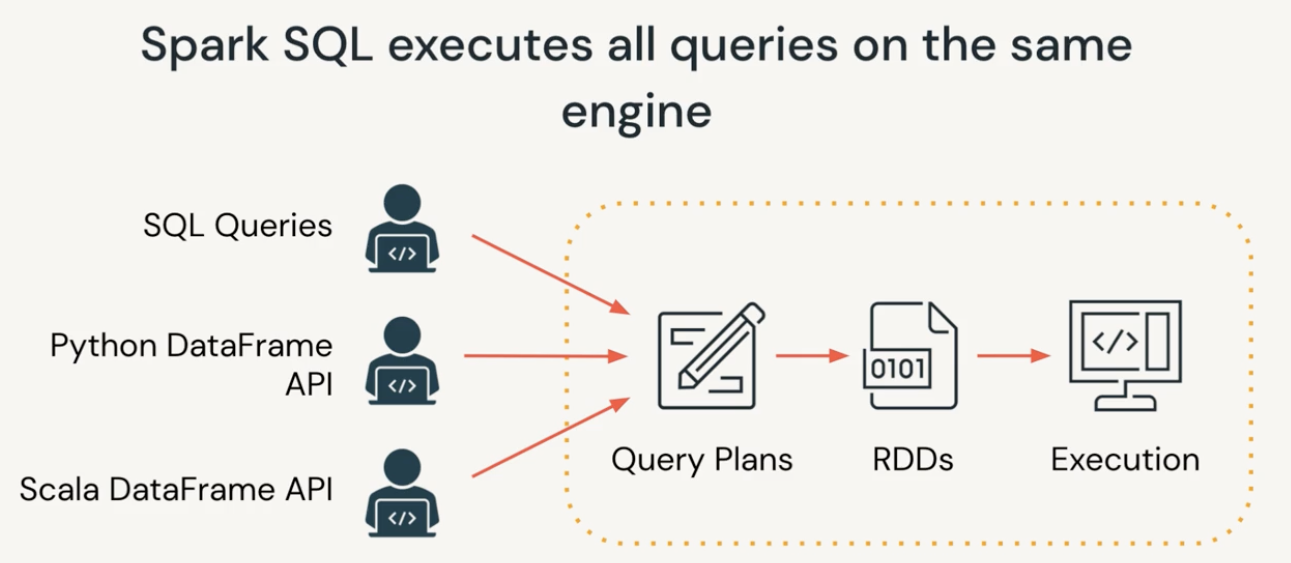
DataFrame API in SparkSQL
DataFrame is immutable collections of data grouped into named columns. Schema defines the column names and data types of a DataFrame.
Read files with Spark DataFrame
You can read data almost all file formats such as CSV, JSON, Parquet, Delta, etc. into Spark DataFrame
You can either choose to inferSchema from the files (expensive with JSON and CSV), or specify schema explitcitly. It's much more efficient to specify schema explicitly, especially for csv and json.
## Read data from parquet files to dataframe
df = spark.read.parquet('path/to/parquet_files').option('inferSchema', True)
## read data from csv specifying separator, header and schema
df = spark.read.csv('path/to/csv_files', sep='t', header=True, inferSchema=True)
## Read data from json files to dataframe
df = spark.read.json('path/to/json_files', inferSchema=True)## Option 1: read data from file with schema specified as StructType
sparkSchema = StructType([StructField('col1', StringType(), True), StructField('col2', IntegerType(), True)]
df = spark.read.csv('path/to/csv_files', sep='t', header=True, schema=sparkSchema)
## Option 2: read data from file with schema specified as DDL syntax
ddlSchema = "col1 string, col2 integer"
df = spark.read.csv('path/to/csv_files', sep='t', header=True, schema=ddlSchema)You can use the StructType Scala method toDDL to have a DDL-formatted string created for you.
%scala
spark.read.json("/mnt/training/ecommerce/events/events-500k.json").schema.toDDLAnd then use a Python cell to copy and paste the previously generated schema in scala to read the files into dataframe
DDLSchema = "`device` STRING,`ecommerce` STRUCT<`purchase_revenue_in_usd`: DOUBLE, `total_item_quantity`: BIGINT, `unique_items`: BIGINT>,`event_name` STRING,`event_previous_timestamp` BIGINT,`event_timestamp` BIGINT,`geo` STRUCT<`city`: STRING, `state`: STRING>,`items` ARRAY<STRUCT<`coupon`: STRING, `item_id`: STRING, `item_name`: STRING, `item_revenue_in_usd`: DOUBLE, `price_in_usd`: DOUBLE, `quantity`: BIGINT>>,`traffic_source` STRING,`user_first_touch_timestamp` BIGINT,`user_id` STRING"
eventsDF = (spark
.read
.schema(DDLSchema)
.json("/mnt/training/ecommerce/events/events-500k.json")
)
eventsDF.display()Write dataframe
## Write data to file
df.write
.option('compression', 'snappy')
.mode('overwrite')
.parquet('path/to/storage')
## Write data to table. If mode('overwrite'), rewrite the whole table. If mode('append'), append data to table
df.write
.mode('overwrite')
.saveAsTable('<table_name>')## write dataframe to Delta, default Parquet format
df.write.format('delta')
.mode('overwrite')
.save('outputPath')Columns in DF
There are many ways to pick a column in DF depending on which language API you use
## Multi ways of extracting columns from Spark DF
%python
df['columnName']
df.columnName
import spark.sql.functions as F
F.col('columnName')
F.col('columnName.field') ##nested column array// Scala
df("columnName")
import org.apache.spark.sql.functions.col
col("columnName")
$"columnName"
$"columnName.field" //nested column arrayColumn Operators & Methods


import pyspark.sql.functions.col
## These are chained transformations
new_df = df.filter(col("colA").isNotNull())
.withColumn("colB", (col("colA")*100).cast("int"))
.sort(col("colB").desc())
## transformations with selectExp
appleDF = eventsDf
.selectExpr("user_id", "device in ('macOS', 'iOS') as apple_user")
## transformation with regular PythonAPI
appleDF = eventsDF.select("user_id")
.withColumn("apple_user", col("device").isin('macOS', 'iOS'))Rows in DF


Data Operations in Spark DataFrame
There are 2 main types of operations you can do with Spark DataFrame.
-
transformations (
select,where,orderBy,groupBy): Remember that DataFrame is immutable so after a transformation, a new dataFrame will be created. Transformation is evaluated lazily until action is invoked or data is touched, not executed immediately but recorded as lineage. There are 2 types of Spark Transformations-
narrow transformation: single input partition computes single output partition (each column are computed separately), without exchange of data (such as
filter,contains). -
wide transformation: data from many partitions read, combined and written to disk (
groupBy,orderBy,count), which causes shuffle of data across partitions
-
-
action (
show,display,take,describe,summary,first, head,count,collect): trigger the lazy evaluation of recorded transformationcountvscollect:countreturns single number to the driver,collectreturns collection of row objects (expensive and can cause out of memory)
Remember that when you specify transformation, your Spark code will not be executed until you call an action on it. Lazy evaluation provide fault tolerance as spark records transformation lineage to restart the job if there’s failure.
SparkSQL Built-in Functions
You can use built-in aggregate functions coming from pyspark.sql.functions for Python and org.apache.spark.sql.functions for Scala. Refer spark sql built-in functions. Built-in functions are highly efficient and best practices for Spark Programming. It’s highly recommended to utilize built-in functions before attempting to create your own UDFs (User Defined Functions)
1. Aggregation functions
All aggregations methods require a groupBy method that returns a GroupedData object
Use the grouped data method agg to apply these built-in aggregate functions

For example:
df.groupBy("col1")
.count().display()
df.groupBy("col1", "col2")
.sum("val1", "val2")
.display()
df.groupBy('col1')
.agg( sum('val1').alias('total1')
avg('val2').alias('average2')
)
.display()df.groupBy('col1')
.agg( sumDistinct('val1').alias('total1')
approx_count_distinct('val2').alias('count2')
)
.display()2. Datetime functions

- Reformat the timestamp column to string representation
import pyspark.sql.functions as F
df.withColumn("date_string", F.date_format("timestamp", "MMMM dd, yyyy")
.withColumn("time_string", F.date_format("timestamp", "HH:mm:ss.SSSSSS")- Extract date time parts from timestamp
df.withColumn('year', F.year(F.col('timestamp'))
.withColumn('month', F.month(F.col('timestamp'))
.withColumn('dayofweek', F.dayofweek(F.col('timestamp'))
.withColumn('minute', F.minute(F.col('timestamp'))
.withColumn('second', F.second(F.col('timestamp'))- Convert timestamp to date
df.withColumn("date", F.to_date(F.col("timestamp"))- manipulate datetimes
df.withColumns("add_2_day", F.date_add(F.col("timestamp"), 2))3. Complex Data Types funtions


Assume we have a DataFrame with items column as nested array. For example:
## For example
from pyspark.sql.functions import F
df
## explode the items field to create a new row for each element in the array
.withColumn("items", explode("items"))
## split column item_name by " " to array
.withColumn("details", split(col("item_name", " ")
## extract the element from details
.withColumn("size", element_at(col("details"), 1)3. Join functions
## inner join
df1.join(df2, 'name')
## inner join with 2 columns
df1.join(df2, ['name', 'age'])
## specify join
df1.join(df2, 'name', 'left')
df1.join(df2, 'name', 'right')
df1.join(df2, 'name', 'outer')
## specify explicit column expressiion
df1.join(df2, df1['customer_name'] == df2['user_name'], 'left_outer')User Defined Functions (UDF) in Spark
In case Built-in Functions are not enough to cover the need, you can write your own custom functions at an efficiency cost.
User-defined function can’t be optimized by Catalyst Optimizer, and must be serialized and sent to executors. Moreover, row data is deserialized from Spark binary format to pass to UDF, then results are serialized back into Spark native format. For Python, they also add overhead to Python interpreter running on each worker node.
Using UDFs can cause serialization issues and long-running Spark job.
A way to fix this is to use Pandas UDF aka Vectorized UDFs using Apache Arrow in Spark 3.x.
To create a UDF, you can follow below steps:
## Step 1: Create a function
def calProfit(sales, cost):
return sales - cost
## Step 2: Register function -> serialize the function and send to executors
calProfitUDF = udf(calProfit)
## Step 3: Apply the udf to the dataframe
df.withColumn("profit", calProfitUDF(col("sales"), col("cost")))
## Register UDF to use in SQL
df.createOrReplaceTempView('sales')
calProfitUDF = park.udf.register("sql_udf", calProfit)-- Use the UDF in sql
%sq
select sql_udf(sales, cost) as profit from salesAlternatively, you can use decorator syntax (only applicable in Python)
## Use Decorator Syntax for Python
## Our input/output is float
@udf("float")
def calProfitUDF(sales: float, cost: float) -> float:
return sales - cost
## use the UDF
df.withColumn("profit", calProfitUDF(col("sales"), col("cost")))Recommend to use Pandas/Vectorized UDFs, notice the difference in syntax
from pyspark.sql.functions import pandas_udf
@pandas_udf("float")
def vectorizedUDF(sales: pd.Series, cost: pd.Series) -> pd.Series:
return sales - cost
## use the UDF
df.withColumn("profit", vectorizedUDF(col("sales"), col("cost")))
## register the UDF for sql
spark.udf.register("sql_vectorized_udf", vectorizedUDF)select sql_vectorized_udf(sales, cost) as profit from sales