


Table of Contents
What is Azure Synapse Analytics?
Azure Synapse Analytics is an integrated data platform that brings together SQL technologies used in enterprise data warehousing such as Dedicated SQL Pool and Serverless SQL Pool, Synapse Spark Pool used for big data, Data Explorer for log and time series analytics, Synapse Pipelines for data integration and ETL/ELT, and deep integration with other Azure services such as Power BI, CosmosDB, and AzureML.
What is Dedicated SQL Pool?
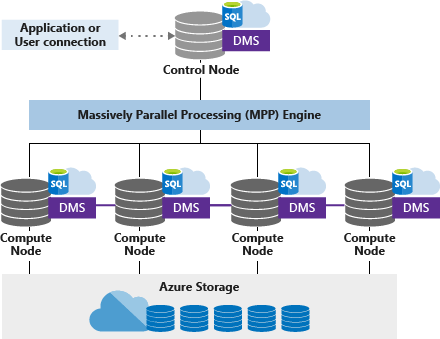
Dedicated SQL Pool (previously SQL DW) leverages a scale-out architecture (Massively Parallel Processing) to distribute computational processing of data across multiple nodes to handle complex analytics queries. Applications connect and issue T-SQL commands to a Control node. The Control node hosts the distributed query engine, which optimizes queries for parallel processing, and then passes operations to Compute nodes to do their work in parallel. The Compute nodes store all user data in Azure Storage and run the parallel queries. The Data Movement Service (DMS) is a system-level internal service that moves data across the nodes as necessary to run queries in parallel and return accurate results. Create table
Users can connect to Dedicated SQL Pool using Azure Data Studio (on Mac and Windows), SQL Server Management Studio (for Windows), and Azure Synapse Workspace web interface.
What is Serverless SQL Pool?
In Serverless SQL pool, there is no need to set up infrastructure and maintain clusters. While in dedicated SQL Pool, we reserved a fixed number of Data Warehouse Units (DWU) which dictate the CPU, Memory and IO power for the data warehouse.
Serverless SQL pool uses a pay-per-use model, so there is no charge for resources reserved, and the charges are made for the data processed by each query that you run. On the other hand, we provisioned our dedicated SQL Pool and pay by Data Warehouse Unit (DWU).
When we query Serverless SQL Pool, we query the external tables, which are abstraction of data in data lake storage. As the result, Serverless SQL Pool doesn’t support indexes for query optimization, or dynamic data masking or column level encryption for permission granting and data security, as well as materialized views. On the other hand, if we import data from the lake to regular tables in Dedicated SQL Pool, we can take advantage of these mentioned features. Dedicated SQL Pool support materialized views but LEFT, RIGHT, OUTER JOIN is not supported in materialized views query creation.
Serverless SQL Pool is suitable for adhoc, simple queries when users must have access to data in our data lake storage account. While dedicated pool can be use for more complex queries suitable for analytics purpose, you also can connect to dedicated SQL pool using a SQL client like Azure Data Studio or SQL Server Management Studio.
Dedicated vs Serverless SQL Pool Comparison
| External table (Serverless Pool) | External Table (Dedicated Pool) | Internal Table (Dedicated Pool) |
|---|---|---|
| No need to set up infrastructure and maintain clusters. Pay per processed queries | Provisioning required, a fixed number of Data Warehouse Units (DWU) which dictate the CPU, Memory and IO power for the data warehouse | |
| Abstraction of data stored in files in ADLS | Abstraction of data stored in files in ADLS | Require data imported from ADLS to the database |
| Native external tables in Serverless SQL pool perform better than Hadoop external tables in dedicated SQL pool in term of query performance | Query is much slower than regular tables and external tables in serverless SQL pools | Query is faster than external tables |
| No support for indexes, dynamic masking | No support for indexes, dynamic masking | Support indexes for faster query selection of rows; dynamic masking; |
| Doesn’t support materialized views, only support views | Doesn’t support materialized views, only support views | Support materialized views but LEFT, RIGHT, OUTER JOIN is not supported in materialized views creation |
| Fast to create. New data in ADLS will be reflected in the table | Is Fast to create as they are just the abstraction. New data in ADLS will be reflected in the table | Takes time to import data from ADLS |
| Pay per processed queries | Pay by Data Warehouse Unit | Pay by Data Warehouse Unit |
| Suitable for adhoc lightweight queries that do summaries, not heavy analytics queries. Users need access to data lake. Synapse Workspace required to access | _ | Suitable for complex queries that serve analytics purpose. Can be connected from client such as Azure Data Studio |