Table of Contents
Reprequisites
To follow along with this tutorial, you will need:
- Azure subscription
- Synapse workspace
- Dedicated SQL Pool
- Azure Databricks workspace in the same subscription
Step 1: Generate Spark dataframe in Databricks notebook
Below spark code generates a dataframe of 3 columns and 100M rows (around 2GB of data)
import random
from pyspark.sql.functions import rand, randn, col, lit
from pyspark.sql.types import StructType, StructField, TimestampType, StringType, DecimalType, IntegerType
schema = StructType([
StructField("purchase_ts", TimestampType(), True),
StructField("customer_id", IntegerType(), True),
StructField("purchase_amount", DecimalType(18,2), True)
])
df = spark.range(100000000)\
.withColumn('purchase_ts', (rand()*1262275200 + 1577836800).cast('timestamp'))\
.withColumn('customer_id', (rand()*(100000000-1)+1).cast('integer'))\
.withColumn('purchase_amount', (rand()*(1001-1)+1).cast('decimal(18,2)'))\
.drop('id')\
.select('purchase_ts', 'customer_id', 'purchase_amount'
Step 2: Create customized login
- In Synapse studio, use master database to create etl login
IF NOT EXISTS (SELECT * FROM sys.sql_logins WHERE name = 'etl')
BEGIN
CREATE LOGIN [etl] WITH PASSWORD='<password>'
END
;
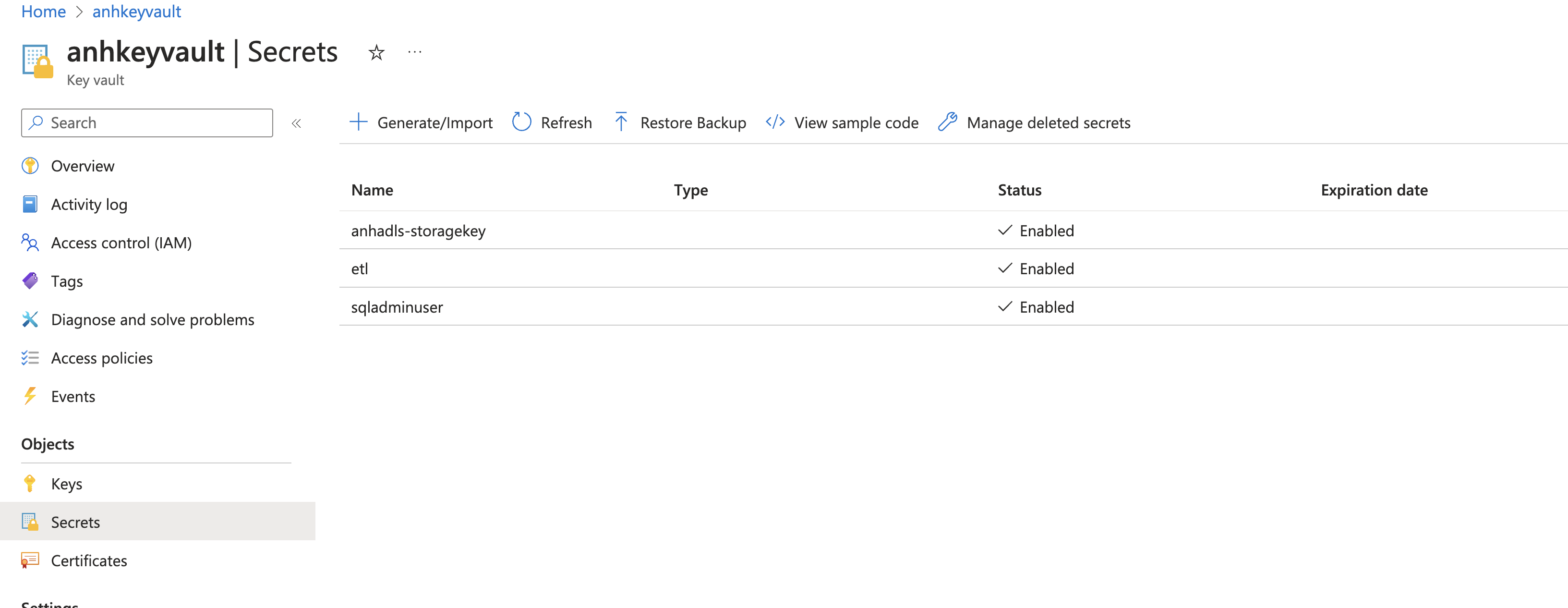
- save elt login password to azure keyvault
- In Synapse studio, create user etl from etl login (use regular database)
IF NOT EXISTS (SELECT * FROM sys.database_principals WHERE name = 'etl')
BEGIN
CREATE USER [etl] FOR LOGIN [etl]
END;
- In Synapse Studio, create workload classifier and specify the workload_group for etl user. You can also specify
-- DROP WORKLOAD CLASSIFIER [wgcETL];
CREATE WORKLOAD CLASSIFIER [wgcETL]
WITH (WORKLOAD_GROUP = 'largerc'
,MEMBERNAME = 'etl'
,IMPORTANCE = normal);
- grant db_owner role to etl user
EXEC sp_addrolemember 'db_owner', 'etl';
Step 3: Use etl login with largerc to write data
- etl user login password can be retrieved from azure key vault secret scope
dbutils.secrets.get(scope='anhkeyvault', key='etl'). To register azure keyvault as secret scope on Databricks, follow this instruction. - If target table does not exist in Synapse, a new table is created with round robin distribution
(
df.write
.format("com.databricks.spark.sqldw")
.option("url", f"jdbc:sqlserver://anhsynapse.sql.azuresynapse.net:1433;database=anh_dedicated_sql;user=etl@anhsynapse;password={dbutils.secrets.get(scope='anhkeyvault', key='etl')};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.sql.azuresynapse.net;loginTimeout=30;")
.option("forwardSparkAzureStorageCredentials", "true")
.option("dbTable", "dbo.purchases")
.option("tempDir", "abfss://temp@anhadls.dfs.core.windows.net/databricks")
.mode("append")
.save()
)
-
Under the hood:
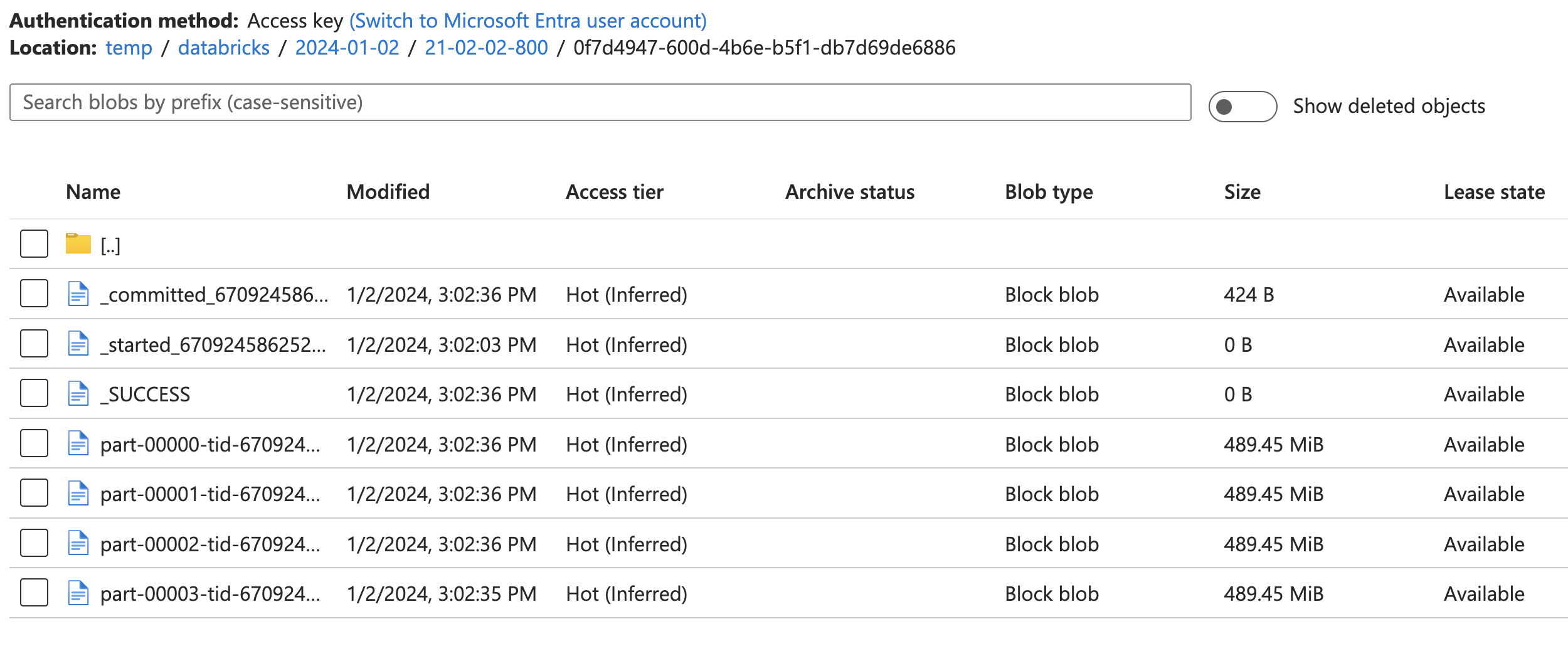
- this code will export the dataframe into parquet snappy format to the specified tempDir cloud storage location. In this case, It took about 33 secs for Spark to export this 2GB of data into 4 snappy parquet files on ADLS cloud storage
-
After that, Azure Synapse will leverage
COPYstatement to transfer large volumes of data efficiently between an Azure Databricks cluster and an Azure Synapse instance using an Azure Data Lake Storage Gen2 storage account for temporary staging (read more here) -
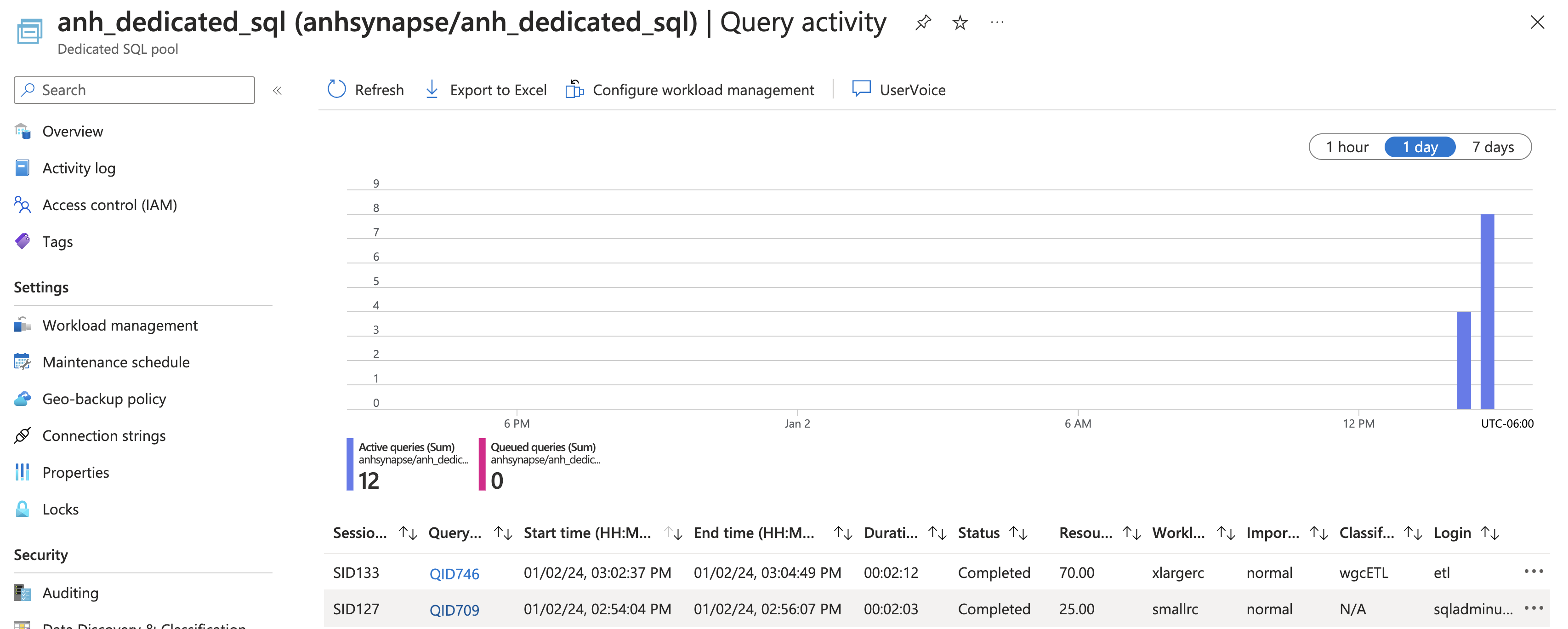
You can go to Query Activity tab in your dedicated sql pool portal to monitor the query. Based on this view, it took around 2 mins to copy around 2GB from cloud storage to Synapse
-
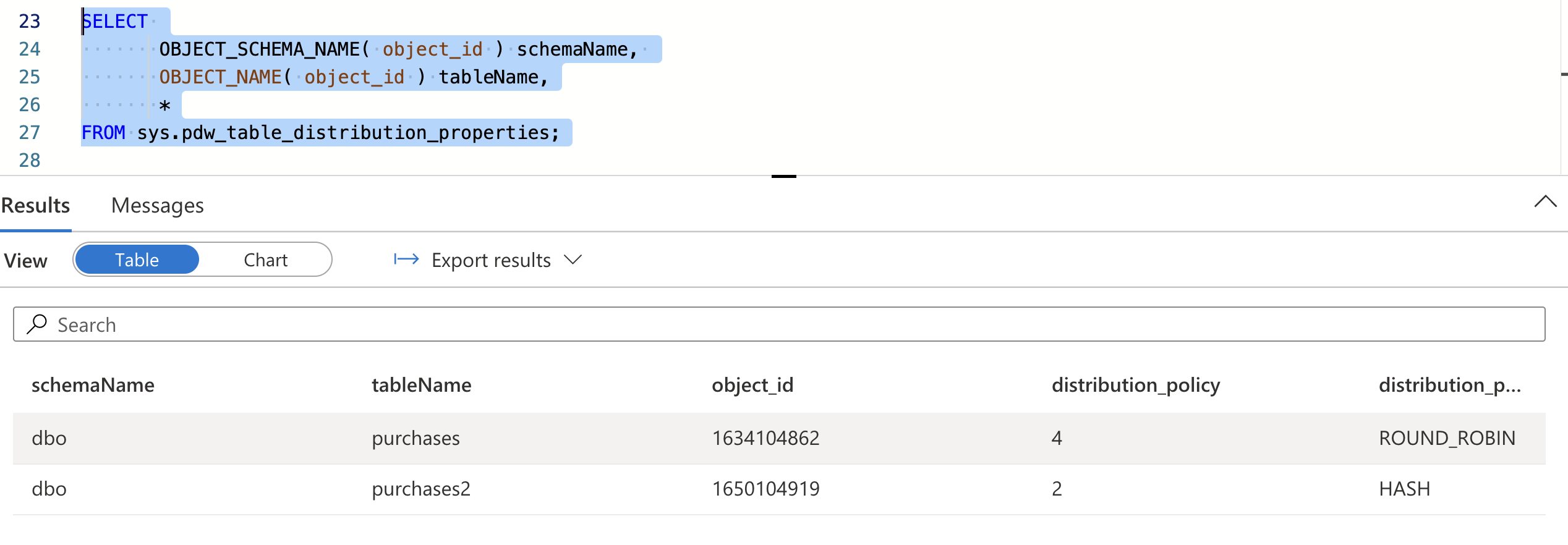
You can also create a hash distributed table with below query in Synapse studio
CREATE TABLE [dbo].[purchases2] ( [purchase_ts] [datetime2](7) NULL, [customer_id] [int] NULL, [purchase_amount] [decimal](18,2) NULL ) WITH ( DISTRIBUTION = hash(customer_id), CLUSTERED COLUMNSTORE INDEX ) GO -
To check distribution of Synapse tables, run below query in Synapse studio
SELECT OBJECT_SCHEMA_NAME( object_id ) schemaName, OBJECT_NAME( object_id ) tableName, * FROM sys.pdw_table_distribution_properties;