


Table of Contents
Metastore and Catalog
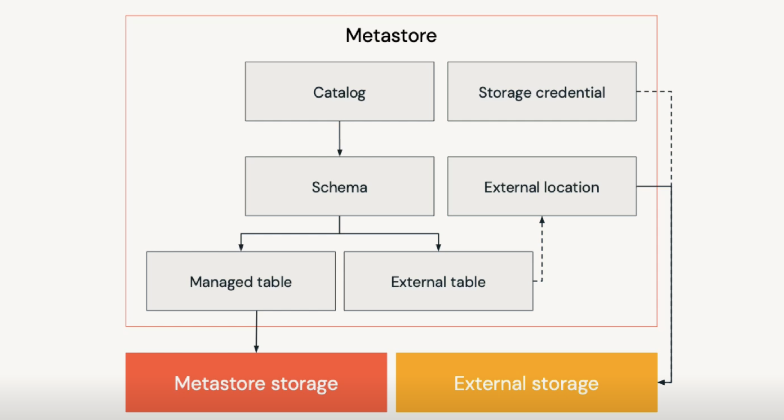
In Databricks, metadata of data Objects (tables, views, etc.) is registered in Metastore.
Previously, Databricks uses Hive metastore by default to register schemas, tables, and views. However, it’s highly recommended to upgrade to Unity Catalog to access centralized access control, auditing, lineage, and data discovery capabilities.
Catalog is a group of databases. If you want to use Unity Catalog, create and specify Catalog is required (Set up and manage Unity Catalog). The Databricks workspace will need to have Unity Catalog enabled as well (Enable a workspace for Unity Catalog)
Databases or Schemas are groups of tables, views, and functions.
Tables are collections of rows and columns stored as files in an object storage. We have managed table, and external table
- Managed tables have data files stored in a managed storage location that is configured into a metastore. When a managed table is dropped, data and its metadata will also be deleted
- External tables have data files stored in a cloud storage location outside of a managed storage location, and only the table metadata is managed in the Metastore. Files for external tables will be persisted in the location provided at table creation, preventing users from inadvertently deleting underlying files.
View is a saved query against once or more tables. Materialized view is only supported with Unity Catalog enabled workspace
Functions are saved logics that return scala values or set of rows
To List the information of these data objects, use below query:
%sql
show catalogs
show schemas in <catalog_name>
show tables in <schema_name>
show views in <schema_name>
show functions
describe schema extended <schema_name>
describe table extended <table_name>
describe detail <table_name>
show create table <table_name>
Schemas and Databases
When create a schema (aka. database), you can use default storage location or provide location
Schema under Default Location
The default location under dbfs:/user/hive/warehouse/ and that the schema directory is the name of the schema with the .db extension.
CREATE SCHEMA IF NOT EXISTS ${db_name}
Running describe schema extended will provide details about the storage location of the schema
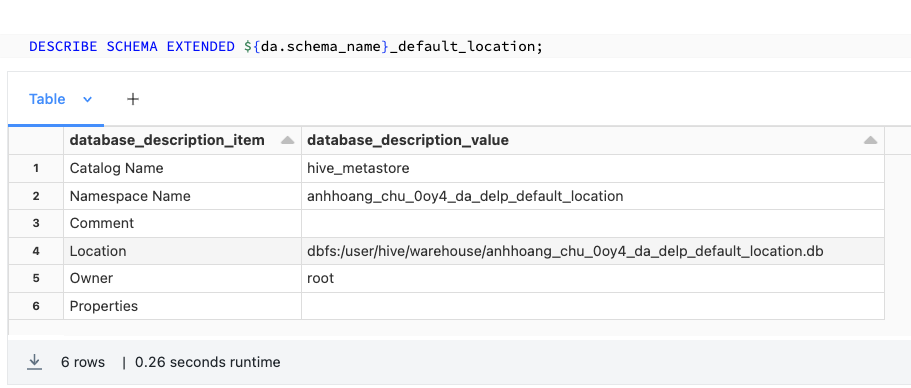
By default, managed tables (data and metadata) in a schema without the location specified will be created in the dbfs:/user/hive/warehouse/<schema_name>.db/ directory.
Schema under Custom location
If you want to create a Schema with a location, the LOCATION associated with a database is always considered a managed location. Make sure to use a new location for each database. Do not register a database to a location that already contains data. Don’t use a location nested under any database location
CREATE SCHEMA IF NOT EXISTS ${db_name} LOCATION 'path/to/empty/location';
%sql
CREATE DATABASE IF NOT EXISTS ${da.db_name}
COMMENT "This is a test database"
LOCATION "${da.paths.user_db}"
WITH DBPROPERTIES (contains_pii = true)
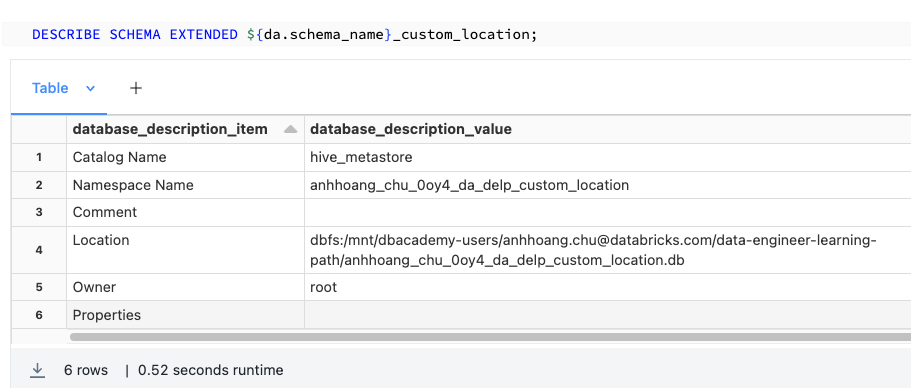
Managed table created in this Schema with Custom Location have data and metadata persisted in the path specified with the LOCATION keyword during schema creation.
Delete Schema (Database)
When schema is dropped, the schema folder, data files and log files are deleted
## Delete Database and all the data
drop schema ${db_name} cascade
When table is dropped, the table folder, data files and log files are deleted; but the schema location remained
drop table ${table_name}
Managed Table vs External Table
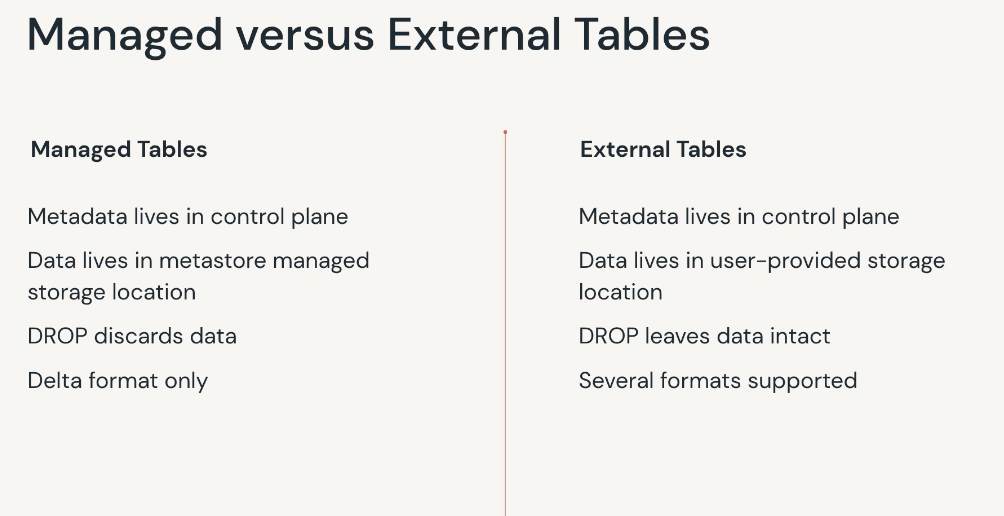
External Table
Query files directly from storage
## query files
select * from csv.`${csv_path}`
select * from json.`${json_path}`
select * from text.`${text_path}`
## Using binaryFile to query a dir will provide file metadata alongside the binary representation of the file contents such path, modificationTime, length and Content
select * from binaryFile.`${unstructured_data}`
CONVERT TO DELTA is an important command that can be used to convert parquet file(s) to a Delta table. This helps in accessing the data as a table and taking advantage of Delta tables.
CONVERT TO DELTA database_name.table_name; -- only for Parquet tables
CONVERT TO DELTA parquet.`s3://my-bucket/path/to/table`
PARTITIONED BY (date DATE); -- if the table is partitioned
CONVERT TO DELTA iceberg.`s3://my-bucket/path/to/table`; -- uses Iceberg manifest for metadata
Create Externals Tables from Files
Sometimes, query files (such as csv) is not advisable because of unpredictable schema format. In these cases, we can create external tables with schema specified
create table table_name (<schema>) using datasource options (key1 = val1, key2 = val2, ...) location = "path/to/data")
CREATE TABLE parquet_external
(field_name1 INT, field_name2 STRING)
using parquet
LOCATION "/path/to/existing/data"
CREATE TABLE json_external
(field_name1 INT, field_name2 STRING)
using json
LOCATION "/path/to/existing/data"
create table csv_external
(col1 string, col2 long, col3 timestamp, col4 integer)
using csv
options (header = 'true', delimiter = '|')
location "${csv_path}"
CREATE TABLE table_name USING DELTA
LOCATION parquet.`/path/to/existing/data`
-- create external table with table properties
CREATE TABLE IF NOT EXISTS schema.pii_table
(id INT, name STRING COMMENT "PII")
COMMENT "Contains PII"
LOCATION "path_to_table/pii"
TBLPROPERTIES ('contains_pii' = True)
With external tables created using above method, data is not moved during table declaration. We still point the queries to files stored in the file paths. Metadata and options passed during table declaration will be persisted to the metastore, so data in the specified location will be read with these options.
%sql
describe extended <external_table>
When external table is dropped, data in the specified location is still persisted. That means if you recreate the external table and point it to the same location, data will show for that table
However, if data in the external tables are not registered as a Delta Lake tables, we may see older cached versions of the data, and freshenesss is not guarantee. The reason is Spark automatically cache underlying data in local storage to ensure optimal performance on subsequent queries. We need to refresh cache by running REFRESH TABLE <table_name>but this will invalidate cache and cause long running query.
You can also read a dataframe from a file location and write it to another
%python
spark.read
.option("headers", "true")
.option("delimiters", "|")
.csv("/path/to/existing/data")
.write
.mode("append")
.format("csv")
.option("path", "/path/to/empty/location")
.saveAsTable("table_name")
Create External Tables from SQL databases
We can also create external tables from SQL databases using JDBC connection. However, make sure to use single-node cluster because the client running in the executors will not be connect to the driver on a multiple-node cluster. We can move the entire source table to Databricks then run queries on this table; or push down the query to external SQL database then transfer the result back to Databricks.
create table
using jdbc
options (
url = "jdbc:{databaseServer}://{jdbcHost}:{jdbcPort}",
dbtable = "{jdbcDatabase}.table",
user = "{Username}",
password = "{jdbcPassword}"
)
Using this method, table is listed as Managed, but data is not persisted locally. We can test using below script
import spark.sql.functions as F
location = spark.sql("DESCRIBE EXTENDED table_name").filter(F.col("col_name") == "Location").first()["data_type"]
## use dbutils to check the files in this storage location
dbutils.fs.ls(location)
This method can incur significant overhead due to network transfer latency of moving data across public internet, execution of query logic in source systems is not optimized.
Managed Table
Files associated with managed tables will be stored to this location on the root DBFS storage linked to the workspace, and will be deleted when a table is dropped.
Additional storage credentials are not needed to manage access to the underlying cloud storage for a managed table.
CREATE or replace TABLE table_name (field_name1 INT, field_name2 STRING) partitioned by (field_name1, field_name2)
CREATE TABLE table_name AS SELECT * FROM another_table
CREATE TABLE table_name AS SELECT * FROM parquet.`path/to/file`
df.write.saveAsTable("table_name")
-- create managed table with property
%sql
CREATE TABLE IF NOT EXISTS ${da.db_name}.pii_test
(id INT, name STRING COMMENT "PII")
COMMENT "Contains PII"
TBLPROPERTIES ('contains_pii' = True)
To access tables information
%sql
Describe extended <table>
describe history <table>
describe detail <table>
## Extract table information
%python
table_location = spark.sql("describe detail {table}").select("location").first()[0]
dbutils.fs.ls(table_location)
View
- The regular view is associated with the current database. This view will be available to any user that can access this database and will persist between sessions.
- The temp view is not associated with any database. The temp view is ephemeral and is only accessible in the current SparkSession.
- The global temp view does not appear in our catalog. Global temp views will always register to the
global_tempdatabase. Theglobal_tempdatabase is ephemeral but tied to the lifetime of the cluster; however, it is only accessible by notebooks attached to the same cluster on which it was created.
create or replace view {name} as select * from {table}
create or replace temp view {name}
create or replace global temp view {name}
SELECT * FROM global_temp.view_name