


Table of Contents
As Dedicated SQL pool uses a scaled-out node based architecture, when creating tables in Dedicated SQL Pool, remember to specify the distribution (sharding strategy) and index for your tables.
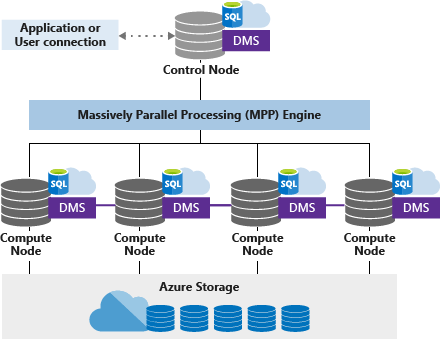
Dedicated SQL Pool Architecture
Choosing Distribution:
The data is sharded into distributions to optimize the performance of the system. You can choose which sharding pattern to use to distribute the data when you define the table. These sharding patterns are supported:
- Hash: deliver the highest query performance for joins and aggregations on large tables. This is most relevant to analytics tables.
- Round Robin: delivers fast performance when used as a staging table for loads, not relevant to analytics queries
- Replicate: provides the fastest query performance for small tables.A table that is replicated caches a full copy of the table on each compute node. Consequently, replicating a table removes the need to transfer data among compute nodes before a join or aggregation. Replicated tables are best utilized with small tables. Extra storage is required and there is additional overhead that is incurred when writing data, which make large tables impractical.
Choosing Index
Besides, you will need to specify the index for your table, there are 3 options:
- CLUSTERED COLUMNSTORE INDEX – default for Synapse Analytics: if table is created without index option specified. Clustered columnstore tables offer both the highest level of data compression and the best overall query performance. Clustered columnstore tables will generally outperform clustered index or heap tables and are usually the best choice for large tables (it’s recommended to use CCI for tables with more than 60 million rows).
- CLUSTERED COLUMNSTORE INDEX ORDER(column [,…n]) : this is a more advanced option for further query tuning (refer: performance tuning with ordered CCI)
- HEAP: it’s best for staging table to load data to dedicated SQL Pool
- CLUSTERED INDEX ( { index_column_name [ ASC | DESC ] } [ ,…n ] ) – default order is ASC: Clustered indexes may outperform clustered columnstore tables when a single row needs to be quickly retrieved. For queries where a single or very few row lookup is required to perform with extreme speed, consider a clustered index or nonclustered secondary index. The disadvantage of using a clustered index is that only queries that benefit are the ones that use a highly selective filter on the clustered index column. To improve filter on other columns, a nonclustered index can be added to other columns. However, each index that is added to a table adds both space and processing time to loads.